感知机
原始形式的感知机是一种简单的线性分类模型,它通过找到一个分割超平面来将数据集分为两类。其数学模型可以表示为:
f(x)=sign(w⋅x+b)
其中,w 是权重向量,b 是偏置项,
且 sign 函数是符号函数,用于输出分类结果(+1 或 -1)。
在训练过程中,权重和偏置的更新规则如下:
- 如果 yi(w⋅xi+b)≤0,即分类不正确 则:
w←w+ηyixi
b←b+ηyi
这里的 η 是学习率,yi 是实际的类别标签。
对偶形式感知机
之前提到w的更新方式是w=w+ηyixi ,如果初始w为零 则w=ηyixi,这里就可以看出来,w实际上就是每个数据的标签yi和数据向量xi作用的结果,每个数据一旦没有被正确分类就会对w作用很多次,下面我们通过一个变量mj来记录数据xj对w的作用次数,从而可以直接表示出w
迭代到最后 结果就是w=ηj=1∑Nmjyjxj (这里相比之前 添加了所有数据对w的影响,之前的也有只是没体现出来)
其中,mj为(xj,yj)在这次之前被错误分类的次数,初始为0
令αj=mjη 则 w=j=1∑Nαjyjxj
代入最开始的迭代式yi(w⋅xi+b)≤0,得到yi(j=1∑Nαjyjxj⋅xi+b)≤0
注意到这个判断误分类的形式里面是计算两个样本xi和xj的内积,而且这个内积计算的结果在下面的迭代次数中可以重用。
如果我们事先用矩阵运算计算出所有的样本之间的内积,那么在算法运行时, 仅仅一次的矩阵内积运算比多次的循环计算省时。 计算量最大的判断误分类这儿就省下了很多的时间,,这也是对偶形式的感知机模型比原始形式优的原因。
之后迭代试如下
- 如果 yi(∑j=1Nαjyjxj⋅xi+b)≤0 其中(j=1∑Nαjyjxj=w),
则:
α∗i←αi+η(α∗j=m∗jη)
b←b+ηyi
收敛后通过公式w=η∑∗j=1Nm∗jy∗jx_j得到权值向量w
参考 刘建平感知机模型
DNN(Deep Neural Network)模型推导
神经网络的基本单元是感知机,但通过增加隐藏层和非线性激活函数,神经网络能够处理更加复杂的非线性问题。
神经网络的结构
- 输入层:接收输入数据。
- 隐藏层:通过权重和激活函数进行计算。
- 输出层:生成最终的预测结果。
参数的定义
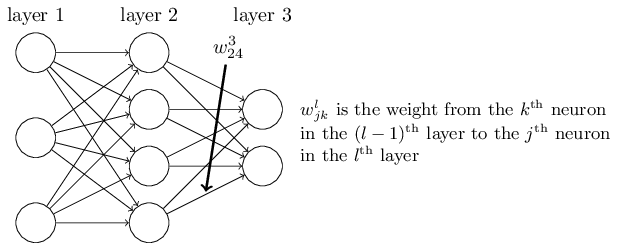
在神经网络中,权重 ( w ) 和偏置 ( b ) 是需要学习的参数。权重 wijl 表示从第 l 层的第 j 个神经元到第 l+1 层的第 i 个神经元的连接权重。
权重 w243 表示第二层的第4个神经元到第三层的第2个神经元的权重。上面代表第几层(从2开始,因为输入层没有变换),下面代表从哪个神经元到哪个神经元,这里是目的和来源相反的。每个w对应一个箭头(变换)
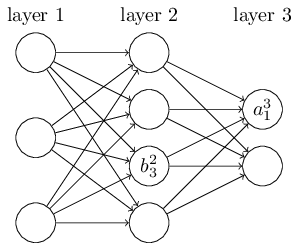
权重 b32 表示第二层的第3个神经元的偏移,上面的次数代表第几层,下面代表第几个神经元,参数b对应于某个神经元
前向传播
前向传播是指从输入层到输出层逐层计算神经元的输出值的过程。假设有一个三层神经网络(输入层、隐藏层、输出层),其计算过程如下:
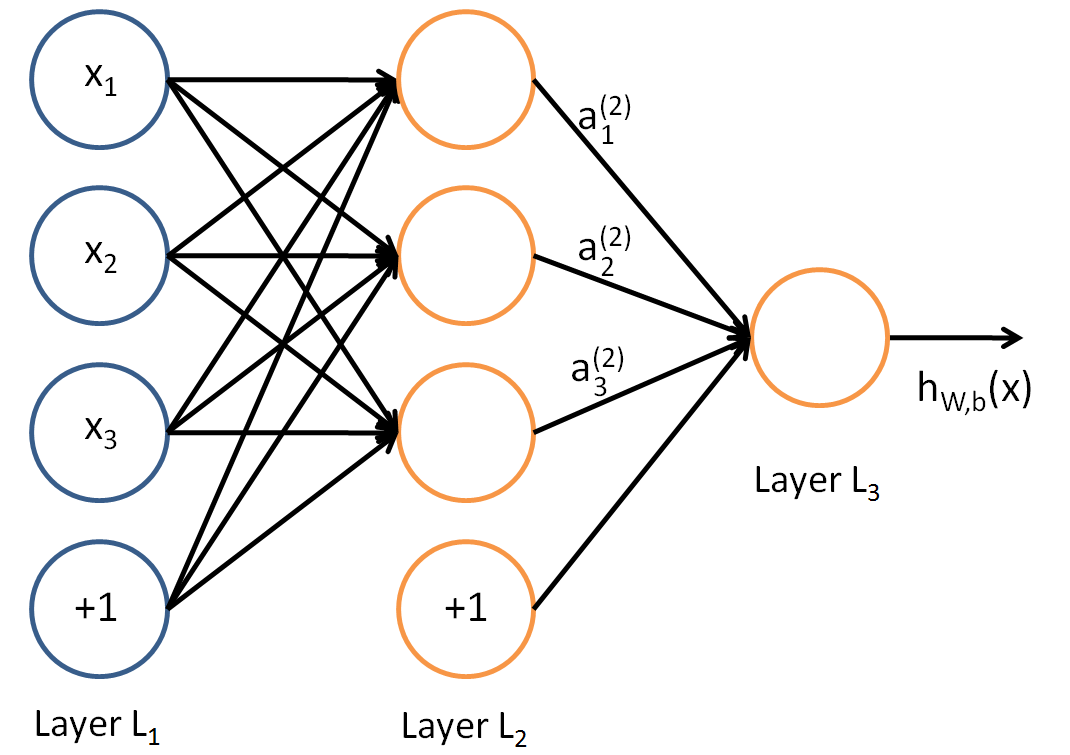
- 输入层到隐藏层:
a12=σ(z12)=σ(w111x1+w121x2+w131x2+b12)a22=σ(z22)=σ(w211x1+w221x2+w231x2+b22)a32=σ(z32)=σ(w311x1+w321x2+w331x2+b32)
- 隐藏层到输出层:
a13=σ(z13)=σ(w113a12+w123a22+w133a23+b13)
其中,σ 表示激活函数(如Sigmoid、ReLU等)。
这里可以简单转化为
ajl=σ(zjl)=σ(k=1∑mwjklakl−1+bjl)
其中m代表前一层神经元的个数,这里l要大于等于2,当l=2时,ak0代表输入x1,...,xn
进而转换成矩阵形式
al=σ(zl)=σ(wlal−1+bl)
反向传播
在这个问题中,您想要了解如何从损失函数 J(W,b,x,y) 对权重 WL 和偏置 bL 的导数推导过程。
损失函数
损失函数 J 定义为均方误差:
J(W,b,x,y)=21∥aL−y∥2=21∥σ(zL)−y∥2
其中 aL 是输出层的激活值,zL 是输出层的加权输入,即 zL=WLaL−1+bL。
对权重 WL 的梯度
为了计算 ∂WL∂J,我们需要使用链式法则。首先,从损失函数对输出层激活 aL 的偏导数开始:
∂aL∂J=aL−y
接着,我们需要 aL 对 zL 的偏导数,这是激活函数 σ 的导数:
∂zL∂aL=σ′(zL)
根据链式法则,∂zL∂J 为:
∂zL∂J=∂aL∂J∂zL∂aL=∂aL∂J⊙σ′(zL)=(aL−y)⊙σ′(zL)
称这个结果为误差 δL:
δL=(aL−y)⊙σ′(zL)
最后,zL 对 WL 的偏导数是前一层的激活 aL−1,因此:
∂WL∂J=δL(aL−1)T
对偏置 bL 的梯度
类似地,zL 对偏置 bL 的偏导数是一个单位向量(zL=WLaL−1+bL,偏置的梯度是误差 δL),因此:
∂bL∂J=∂aL∂J∂zL∂aL∂bL∂zL=δLI=δL
递推
在实际应用中,知道δl+1(最开始是δL)后,要知道δl需要使用数学归纳法
δl=∂zl∂J=(∂zl∂zl+1)T∂zl+1∂J=(∂zl∂zl+1)Tδl+1
其中,∂zl∂zl+1需要推导
zl+1=Wl+1al+bl=Wl+1δ(zl)+bl
对zl进行求导
∂zl∂zl+1=Wl+1diag(σ′(zl))
从而
δl=(∂zl∂zl+1)Tδl+1=(Wl+1diag(σ′(zl))Tδl+1=(Wl+1)Tδl+1⊙σ′(zl)
因此只需要求出最后一层的δL就可以推导出前面的