介绍
PCA的目的是找到一个矩阵将数据降维的同时 最大程度保留原始数据的信息
通过证明可以得出这个矩阵就是原数据(标准化)协方差矩阵的特征向量矩阵
协方差(covariance)矩阵cov定义为covi,j=m1i,j∑m(xi−μ)T(xj−μ)
如果数据集X∈Rn∗d 则cov∈Rd∗d 也可以是cov∈Rn∗n
前者反应了各个特征之间的变化关系 对角线为各个特征的方差 特征向量矩阵更加易于理解
后者反应了各个数据的差异 对角线是数据的二范数 特征向量矩阵比较抽象 但仍然包含了主成分
当数据量小于特征数量的时候使用后者 协方差选取不同后面降维时映射矩阵乘的方向就不同
其中a和b是特征序号
因为数据是标准化后的 因此μi为0
推导
可以从两个方面出发进行证明
最小化重构误差
数据X∈Rd∗n 投影矩阵A∈Rd∗r 投影后ATX 再重构恢复数据为AATX
希望恢复后与原来的数据差距最小 等价于
argminA∥X−AATX∥F2 s.t.ATA=I
∥X−AATX∥F2=tr[(X−AATX)T(X−AATX)]=tr[XTX−2XTAATX+AATXTAATX]=tr(2XTX−2XTAATX)
其中XTX为定值
原式等价
argmaxAtr(ATXXTA)s.t.ATA=I
最大化散度
argmaxA∥ATX−ATμ∥F2 s.t. ATA=I
其中μ=n1i=1∑n(xi),原数据经过归一化,平均值为0
则原式
∥ATX∥F2=tr(ATXXTA)
即二者都等价于
argmaxAtr(ATXXTA) s.t. ATA=I
构造拉格朗日函数 并对A求偏导令其为0
J(A,λ)∂A∂J=tr(ATXXTA)−λ(ATA−I)=2XXTA−2λA=0⇒XXTA=λA
这里的A就是XXT的特征向量矩阵,λ为特征值矩阵(diag(λ1,...,λd))
问题
计算完特征矩阵后,要将特征向量根据特征值进行排序进而选取前k(希望降到的维数)个特征向量,为什么要根据特征值选取特征向量?
选取特征向量时,肯定要优先选取包含信息最多的k个向量,因此这个问题就是为什么特征向量大就包含的信息多
假设y1为第一个主成分 则有y1=αiTX 其中αi为含有信息量第一的的特征向量,有αiTαi=1
我们希望y1的方差最大,
其中y的方差
var(y1)=var(αiTX)=E[(y1−μ′)(y1−μ′)T]=αiE[(X−μ)(X−μ)]αiT
其中间部分即为X的协方差矩阵 记为∑
则优化式为(这里限制条件是指αi是一个单位向量)
argmaxαi J(αi,λ)∂αi∂JαiT∑αi s.t. αiαiT=1=αiT∑αi−λ(αiαiT−1)=2∑αi−2λαi⇒∑αi=λαi
结论带入原式
αiT∑αi=αiTλαi=αiTαiλ=λ
也就是说 方差等价于λ 即特征值 特征值越大 映射后的数据方差也就越大
下面继续证明第二个主成分y2对应的特征向量为第二大的特征值对应的向量
待优化式(其中第二个限制条件是指特征向量每每正交)
argmaxαi J(αi,λ,θ)∂αi∂J带入原式有αiT∑αi s.t. αiαiT=1,αiTα1=0=αiT∑αi−λ(αiTαi−1)−θαiTα1=2∑αi−2λαi−θα1=2αiT∑αi−2λαiTαi−θαiTαi=0⇒θ=0∑αi=λαi
从而同样可以得出 降维后方差等于特征值的结论
依次类推 可以通过yk−1推得yk为特征矩阵时 降维后方差与特征值的关系
因此 可以得出 降维后的方差和特征值是等价的 所以将特征值按降序排列后 依次选取的特征向量就是包含信息量最多的前几个特征值
直觉上的理解
如下图,原数据A,B,C要投影到y1
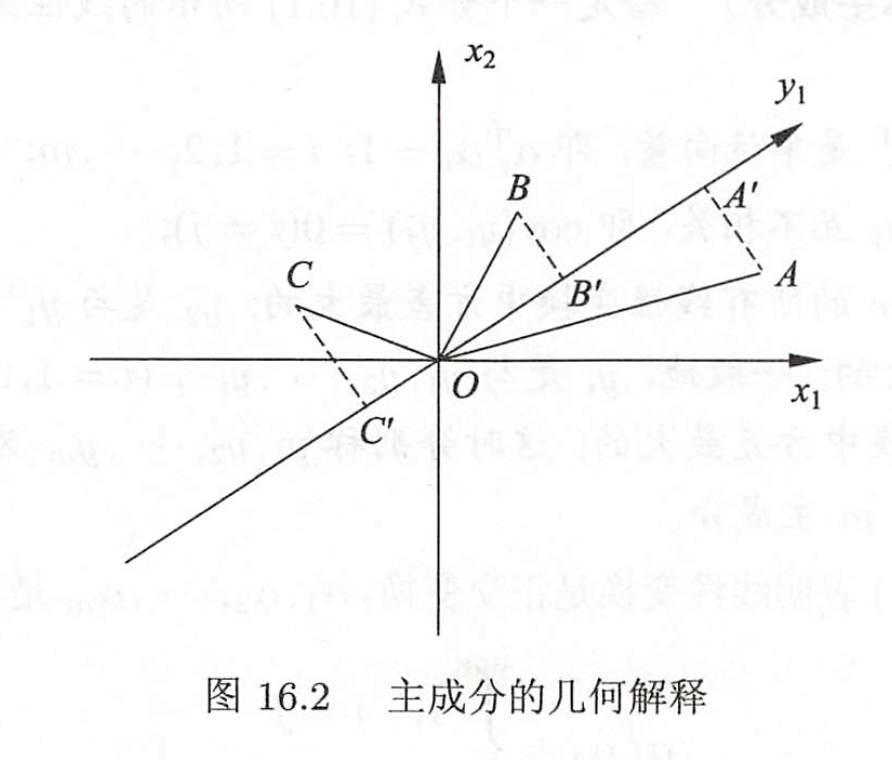
假设数据已经经过归一化 原数据的方差OA2+OB2+OC2固定
最大化散度即最大化OA‘+OB‘+OC‘
在三角形OAA‘中 OA固定 最大化OA‘即最小化A‘A 也就是最小化重构误差
pca原理1pca原理2
来源: 李航:统计学习方法(第二版)